横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

Hololens利用SLAM技术解决两个问题:我在哪儿(定位)?我周围有什么(三维场景重建)?
HoloLens把科幻电影中许多全息投影的桥段,真真切切地带到了现实生活中。和Google Glass只能在头部固定位置看到个小屏幕不同,HoloLens把全息场景和现实世界融合到一起,让你感觉全息场景就在那儿,就是现实世界的一部分。

要做到这种效果,Hololens首先面临两个问题:我在哪儿(定位)?我周围有什么(三维场景重建)?解决这两个问题的关键就是SLAM(Simultaneous Localization and Mapping),即时定位与地图构建。

三种传感器扮演什么角色?
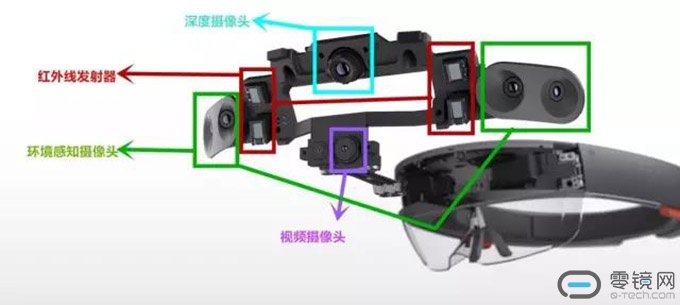
HoloLens上有4个环境感知摄像头、1个深度摄像头、1个IMU(惯性测量单元)。这些传感器分别起什么作用呢?为了让你更直观地了解到,我们可以先做个小测试。
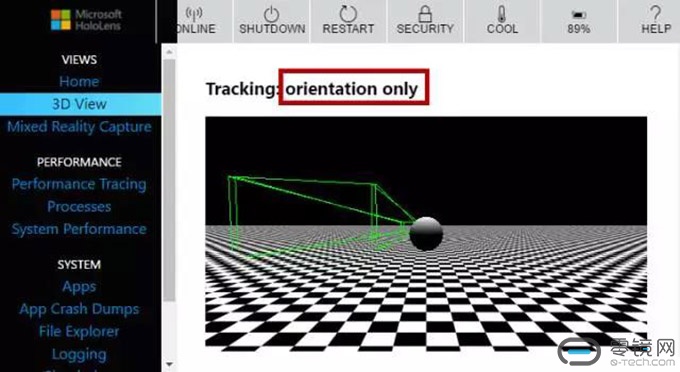
首先,我们把环境感知摄像头和深度摄像头都遮住,只让IMU起作用。

通过Windows Device Portal的3D View查看到如下结果。这个时候HoloLens只能知道方向,不能知道相对位置偏移,也不能对周围环境建模。可以看出,IMU负责感应设备的方向。
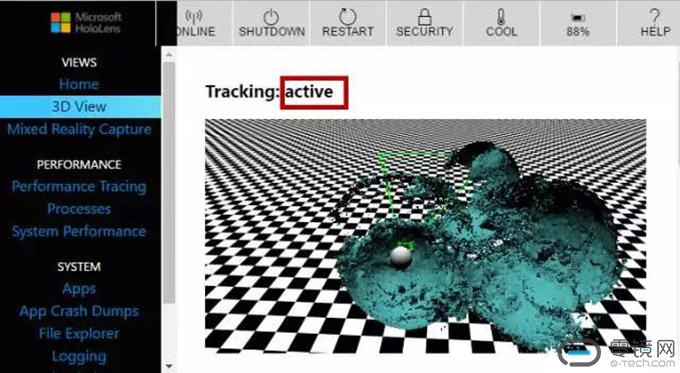
然后,我们把4个环境感知摄像头遮住,只露出深度摄像头。结果和上面一样——不知道相对位置偏移,也没有对周围环境建模。可以看出深度摄像头对空间建模并不会单独起作用。

接着,我们把深度摄像头遮住,只露出4个环境感知摄像头,分别在房间三个位置扫描周围环境。

结果如下图所示:每个位置建模形状接近球体,构建的三维环境模型是不正确的。但三个扫描的位置是正常的,所以这个时候,HoloLens是可以感知在真实空间中的相对位移和朝向角度。可以看出环境感知摄像头负责感应设备相对位置的偏移,但不会对周围环境建模。HoloLens的定位并不依赖深度摄像头。
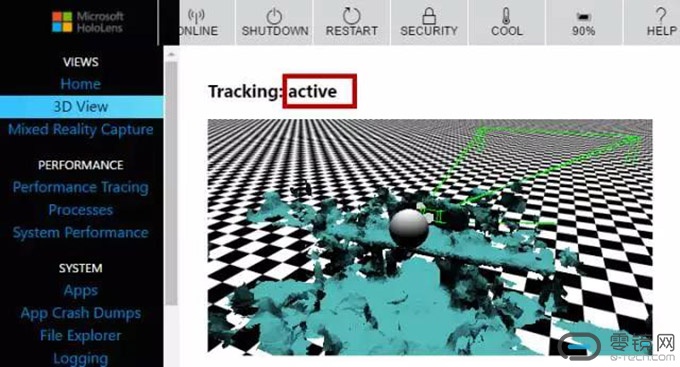
最后,我们什么传感器也不遮,看看正常情况.如下图所示:HoloLens既可以感知在真实空间中的相对位移和朝向角度,又可以对周围环境建模。可以看出,深度摄像头需要依赖环境感知摄像头去认知还原周围环境。
根据上面的小测试,你应该可以大致了解这三种传感器的作用:IMU感应HoloLens的方向,环境感知摄像头感应HoloLens相对位置的偏移,深度摄像头感知HoloLens周围环境。
关键的深度摄像头
IMU和4个环境感知摄像头负责解决“我在哪儿”问题,再加上深度摄像头后解决“我周围有什么”问题。深度摄像头和普通摄像头的不同就是能够获得拍摄对象的深度信息,也就让HoloLens获得了环境三维立体数据(如下图所示)。

从之前的测试可以知道,定位离不开环境感知摄像头,而三维环境构建也不仅仅依赖深度摄像头。那么问题来了,环境感知摄像头是怎么知道HoloLens在空间中的位置呢?深度摄像头又是如何重建三维场景呢?这就涉及到了SLAM。
SLAM作为一个三维感知的基础技术并不新鲜,SLAM从提出到现在已经三十多年,用于解决实现机器人的自主定位和导航。微软的SLAM项目早在2001年11月5日就已创立,目前SLAM体系发展已经相当庞大。
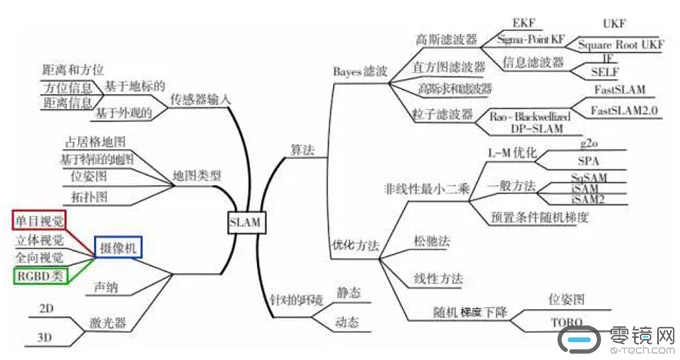
今天我们只谈HoloLens使用的技术,就是摄像机里的单目视觉和RGBD类。
单目视觉,就是依靠一个摄像头去完成SLAM。HoloLens正是用单目SLAM,首先提取图像中的特征,然后根据相邻帧图像的特征去匹配,识别出场景某些特征点位置,并通过图像的变化反向计算出相机的运动。
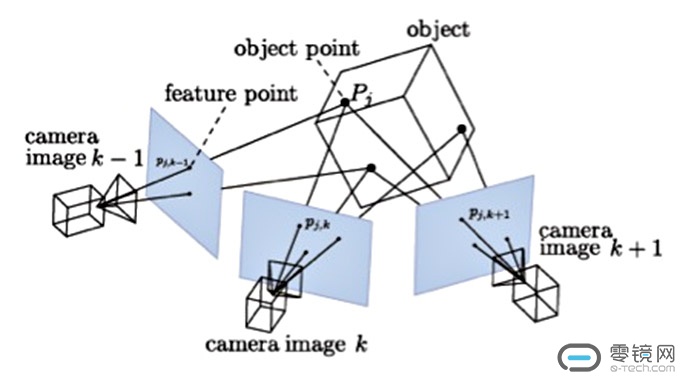
HoloLens有4个环境感知摄像头,靠内的两个摄像头朝向前方,靠外的两个摄像头分别朝向左右两边。主要起作用的是靠内的摄像头,只要靠内的摄像头有一个不被遮挡,即使其他三个摄像头被遮挡,也不会影响HoloLens对空间位置的感知。

由于有深度摄像头,HoloLens并不需要靠环境感知摄像头去获得场景每个像素的深度值,只需要根据一些匹配上的关键特征点计算出摄像头相对场景位置即可。否则仅仅依靠环境感知摄像头计算场景所有深度信息,代价相当大。
RGBD类最大的特点是可以通过红外结构光或Time-of-Flight原理,直接测出图像中各像素离相机的距离。因此,它比传统相机能够提供更丰富的信息,也不必像单目或双目那样费时费力地计算深度。HoloLens的深度摄像头用的便是Time-of-Flight原理,即通过从投射的红外线脉冲反射回来的时间来获得深度信息。使用红外线测深,也正是HoloLens对黑色表面识别不好的原因。

HoloLens的三维场景重建利用的是Richard Newcombe发明的Kinect Fusion。为了更好理解Kinect Fusion,可以想象下,我们在玩雕塑。先是有一个巨大的方块,我们从一个角度去挖,挖到想要成型样子的表面就不挖了。挖多深,用的就是深度图的信息。然后不断换角度,继续重复上面的过程,这样多个角度后,雕塑的样子就慢慢浮现出来。

具体重建三维场景流程如下图。
a)读入的深度图像转换为三维点云并且计算每一点的法向量。
b)相机的追踪。Kinect Fusion是计算得到的带有法向量的点云,和通过光线投影算法根据上一帧位置从模型投影出来的点云,利用 ICP算法配准计算位置,但深度摄像头的精细度并不高,如果HoloLens采用深度图数据来计算HoloLens位置,误差会挺大,全息场景也不会稳定固定在空间里。相机的位置是利用环境感知摄像头计算出来的。
c)根据相机的位置,将当前帧的点云融合到网格模型中去。
d)根据当前帧相机位置利用光线投影算法从模型投影得到当前帧视角下的点云,并且计算其法向量,用来对下一帧的输入图像配准。
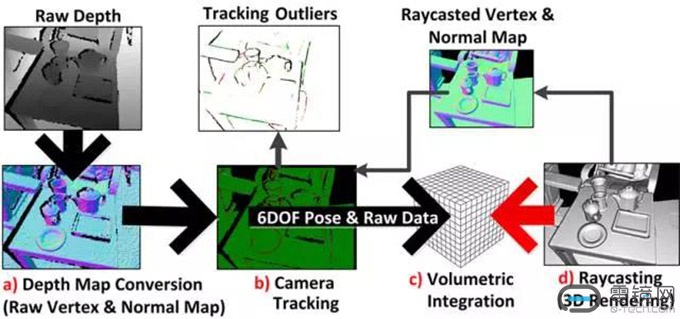
如此循环,就可以通过移动相机获取场景不同视角下的点云,重建完整的场景表面。
写在最后
现在,你应该明白HoloLens中的SLAM技术是如何工作的吧。目前对SLAM的研究还在继续,由于产品和硬件高度差异化,而SLAM相关技术的整合和优化又很复杂,导致算法和软件高度碎片化,市场上真正能在实际应用中运用SLAM的产品不多。而能够将IMU 、环境感知摄像头、深度摄像头各取所长,正是HoloLens的优势所在。
整理自微软HoloLens官方公众号












