横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

2017年10月19日,DeepMind在《Nature》杂志发布了其最新研究成果阿尔法元(AlphaGo Zero),题目很吓人,叫《无须人类知识掌握围棋》,并正式推出人工智能围棋程序的一个最新版——阿尔法元(AlphaGo Zero),让业界为之一震。
新版的AlphaGo计算能力空前强大,完全从零开始,不需要任何历史棋谱的指引,3天超越AlphaGo李世石版本,21天达到Master水平。百战百胜,棋艺增长远超阿法狗, 击溃阿尔法狗100-0。这是迄今最强大的围棋程序:不需要参考人类任何的先验知识,完全靠自己一个人强化学习(reinforcement learning)和参悟,直接采用自对弈进行训练。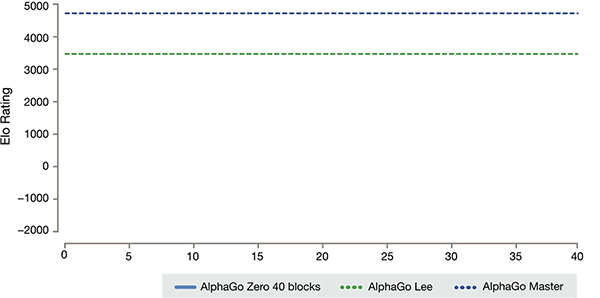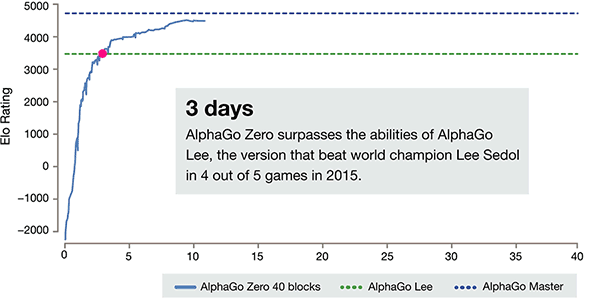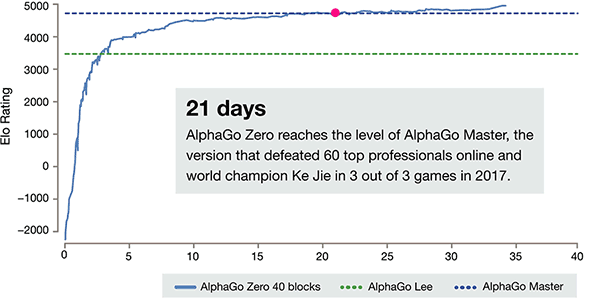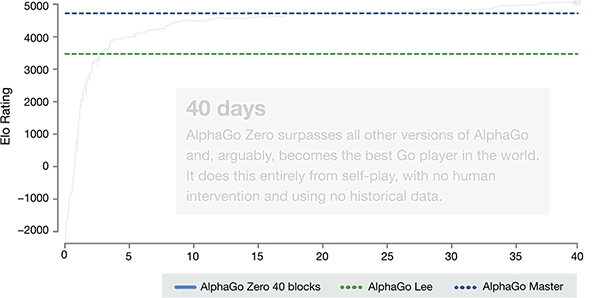
新一代的达到这样一个水准,只需要在4个TPU上,花三天时间,自己左右互搏490万棋局。而它的哥哥阿法狗,需要在48个TPU上,花几个月的时间,学习三千万棋局,才打败人类。 为什么阿尔法元能够完全自己学习?它依靠的到底是什么?
?为什么阿尔法元能够完全自己学习?
在这里我们先来聊聊阿尔法狗为何总和围棋过不去,因为围棋巨大的搜索空间和对棋盘位置和走子精确评估的困难,在很长时间里围棋被视作人工智能最具有挑战性的传统游戏。而AlphaGo的前几代版本,一开始用上千盘人类业余和专业棋手的棋谱进行训练,学习如何下围棋。AlphaGo Zero则跳过了这个步骤,自我对弈学习下棋,完全从乱下开始。
AlphaGo Zero之所以能当自己的老师,是用了一种叫强化学习的新模式。AlphaGo Zero 采用了一个带参数的深度神经网络,对棋盘上的每个位置,都会与那个带参数的神经网络相结合,使用蒙特卡洛搜索树来搜索出每一步落子可能性的价值,并且经由一个判断环节来选择其中最可能赢的落子方式。输入的信息是位置信息和历史下法,输出的信息是可以落子的可能位置和每个可能位置的价值。
系统从一个对围棋一无所知的神经网络开始,将该神经网络和一个强力搜索算法结合,自我对弈。在对弈过程中,神经网络不断调整、升级,预测每一步落子和最终的胜利者。AlphaGo Zero 完全不使用人类的经验棋局和定式,只是从基本规则开始摸索,完全自发学习。
升级后的神经网络与搜索网络结合成一个更强的新版本AlphaGo Zero,如此往复循环。每过一轮,系统的表现就提高了一点点,自我对弈的质量也提高了一点点。神经网络越来越准确,AlphaGo Zero的版本也越来越强。使用了更先进的算法和原理,让AlphaGo Zero的程序性能本身更加优秀,而不是等待硬件算力技术的提升。
虽然这种技术比此前所有版本的AlphaGo都更为强大,但是训练完成的AlphaGo Zero只能给人们发现它自学成才的许多围棋打法与人类上千年来总结的知识是不谋而合的,比如打劫、征子、棋形、布局在对角等,都有人类围棋的影子。
在人类下象棋的历史中,曾经发明过许多“定式”。这可以看成是局部的最优解,双方只要都按照这种定式来下棋,就会取得相同的优势。在十个小时左右的时候,AlphaGo Zero 发现了简单的定式;在十六个小时左右,发现了“小雪崩定式”。之后随着棋局的增多,AlphaGo Zero 的棋力越来越强,直到超过了人类目前能够掌握的棋力,超越了之前的世界最强AlphaGo。

所以人类棋手也不用伤心,这恰恰证明人类在过去的几千年里摸索出了围棋这一游戏的“自然规律”,而人工智能与人类棋手的对比就像是汽车和跑步。每下一步仅需要思考是0.4秒的AlphaGo Zero所产生的美感与人类在紧张对弈时的美感是完全不同的,就像没有人会把F1方程式当赛跑比赛看一样。
它依靠的到底是什么?
报道中常说的“自学成才”其实表达的不算很准确,下棋有多少种走法,机器可以判断,人却没有那么大的计算量。围棋的下法总计3的361次方,这个数字极其庞大,比整个宇宙原子总和还要多,因此利用暴力穷举法来验证所有走法的可行性显然不切实际。
David Silver说,很多人相信在人工智能的应用中算力和数据是更重要的,但在AlphaGo Zero中他们认识到了算法的重要性远高于算力和数据——在AlphaGo Zero中,团队投入的算力比打造上一个版本的AlphaGo少使用了一个数量级的算力。

AlphaGo广为人知的三个部分分别是策略网络、价值网络和蒙特卡洛树搜索。
第一个部分:策略网络
它所代表的是人类的经验、历史的经验。从公开的论文来看,AlphaGo的策略网络准确度基本在57%。这个比喻未必特别精确,但类比考试成绩,如果期末考试才考了57分,这个成绩在人类世界就有点拿不出手了,这能说明什么?
这个说明了策略网络和人类可以学到的相比并不是特别厉害,所以Zero在Master之后必然从头开始寻找更优策略。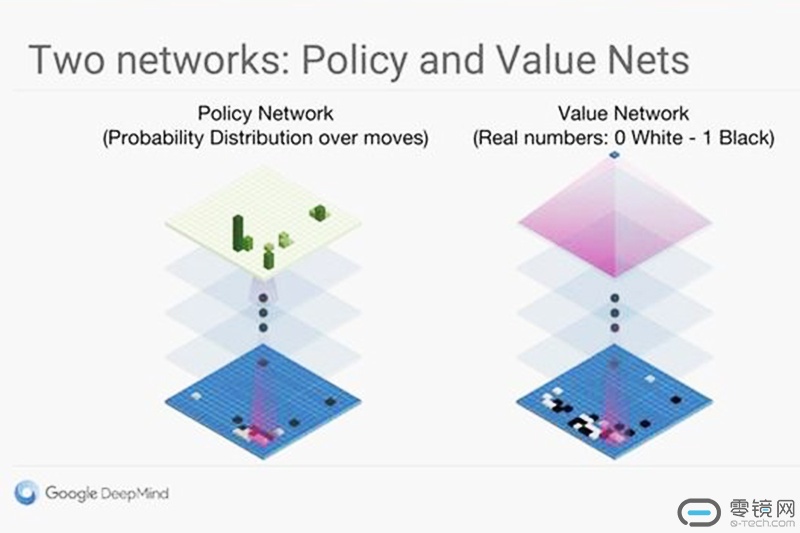
第二个部分:价值网络
根据实践,价值网络特别不好训练,很难获得一个质量特别好的结果;也就是说价值网络评估当前棋局形势的能力其实也不如人类。
第三个部分:蒙特卡洛树搜索
人类每下一步棋,能考虑到几十步已经是顶尖的高手,但AlphaGo使用蒙特卡洛树搜索却可以搜索几十万、几千万、几亿步。那不就是高手中的高高手了嘛!
所以综上所述,在策略网络和价值网络都不如人类的情况下,AlphaGo为什么还能这么厉害?最根本的原因还是在于它使用的蒙特卡罗树搜索这块能力比人强。
这个再次证明了人脑的强大!因AlphaGo Zero是程序员开发出来的!程序员用算法大脑打败了人类职业棋手几千年积累的经验大脑!这足以说明,在任何需要计算的领域,一定有比经验更可靠、更精确、价值最大的最优选择!
下面举个浅例来简单说明,首先我们观察棋盘,容易发现它是一个中心的对称的,也就是假设黑子第一手下在右上角星位,白子第一手下在左下角星位,实质上和第一手下在左下角星位,白子第一手下在右上角星位是一样的,只要棋盘顺时针转180度,盘面就完全一样,而在围棋的下法里,这算两种下法,这样我们就能省去接近75%的重复图形。
然而仅仅减去这么多显然还不够,我们发现有些棋显然无意义或不能放,比如按照棋规,棋不能放在对方的眼位里,又或者送给别人征子的自杀棋(弃子不算),这些算起来可以排除将近99.9%的无用的计算,但这仍然不够,所以下面就要形成一些定式,即虽然你不知道所有走法的对错,但你知道某些走法一定对,那你开局就往这方面去走,一旦对手走错就速败,走对了也只是均势而已。
最后,我们知道随着棋盘子摆的越来越多,复杂度就急剧下降,所以胜负往往在中盘就已决定了,后期AI转用穷举法足够应对,翻盘几乎不可能。
零镜观点:
人工智能时代已经到来,围棋作为人工智能的试金石,目前阶段的展示已然让我们不寒而栗!而阿尔法元的成功证更是明了记忆的价值含量并不高,是最原始的存储方式,并非思考方式,从方法上下功夫比死记硬背强得多,可以说阿尔法元已经从样本进化过度到方法的进化。所以,Zero的诞生,其进步意义就是,人机大战再无意义!围棋将回归其本来面目,那是什么?












