横排-无底-140x48mm-04-1.png "前沿科技阵地")
竖排-无底白字-280x96mm-04.png "前沿科技阵地")

近年来,基于深度学习的人工智能在各大科技公司的产品上出现,而大部分公司主要采用两种资源驱动深度学习:一是、云端提供的廉价的处理能力;二是、大量的用户数据。对于苹果公司来说却无法采用以上两种方式,因为果对用户隐私的承诺,使得苹果在人工智能研究领域的作用也不那么积极,它既无法积累有用的机器学习数据集,培养新的算法;也无法吸引Facebook、谷歌和其他硅谷巨头的那些研究人才。所以苹果在诸如地图和照片,与谷歌和其他更强大的人工智能软件的优势相形见绌,在智能家居等新的利润丰厚的市场上处于严重劣势。
那么苹果是如何将数据不发到云的情况下提供AI深度学习?它又是如何从一开始就得到这些数据的呢?
苹果的深度学习功能按苹果公司的说法都是发生在用户的设备上,如照片中的面部识别和信息中的会话建议。苹果公司的CraigFederighi说:“当涉及到对你的数据进行分析的时候,我们是在你的设备上做的,把你的个人数据放在你的控制之下。”相比之下,谷歌则是在云端。
苹果表示:它们使用的是“差别隐私”技术,在保持用户匿名的同时,对用户的数据进行梳理。这包括散列、细分和噪声注入等技术,对自己的数据进行置乱。这使得理论上很难追踪到单个用户的信息,所以仍然为苹果的计算机科学家提供可行的数据集来训练他们的深度学习工具。 同时也正是因为苹果的隐私保护,导致了其人工智能受到用户隐私承诺的束缚。所以苹果的智能语音助手在本地运作就得面对各种壁垒。使用时可能会慢一些(只在你的手机上工作,而不是服务器架),可能会更大(下载所有这些神经网络模型),而平衡这些限制可能意味着Siri最终无法像竞争对手谷歌和亚马逊的人工智能语音助手那样正常工作。
同时也正是因为苹果的隐私保护,导致了其人工智能受到用户隐私承诺的束缚。所以苹果的智能语音助手在本地运作就得面对各种壁垒。使用时可能会慢一些(只在你的手机上工作,而不是服务器架),可能会更大(下载所有这些神经网络模型),而平衡这些限制可能意味着Siri最终无法像竞争对手谷歌和亚马逊的人工智能语音助手那样正常工作。
苹果的人工智能部门在Giannandrea控制下是否能拯救Siri!
谷歌(Google)前搜索和人工智能主管约翰·詹南德雷亚(JohnGiannandrea)这位53岁的苏格兰工程师在近日获得了新的头衔和职位:苹果的机器学习和人工智能战略主管。
这意味着他将苹果最重要的两个人工智能产品:核心ML和Siri结合在一起。ML是苹果的应用程序机器学习框架,它帮助开发者在移动设备上顺利地运行人工智能工具,对于苹果而言,保持其作为世界上最先进应用程序的发源地的领先地位是至关重要的。
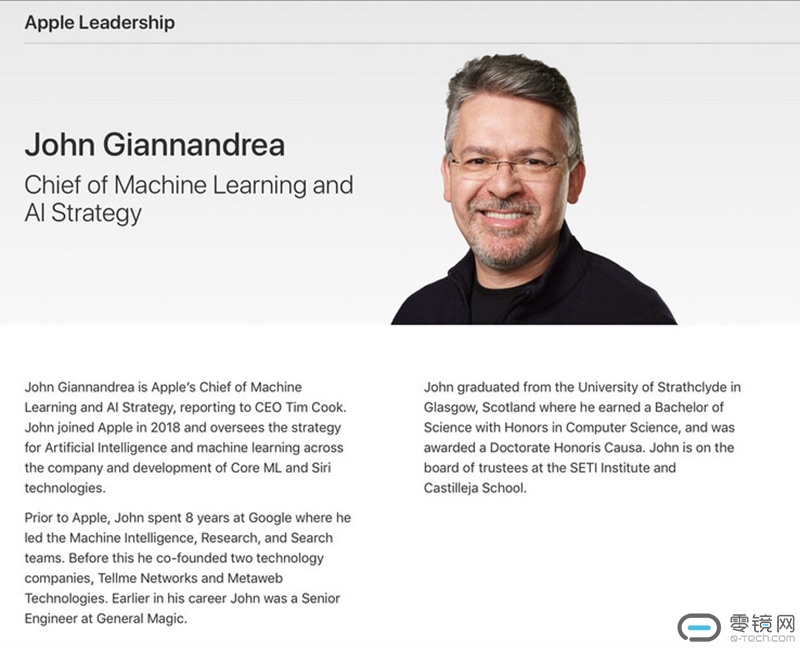
苹果在自然语言处理和计算机视觉等关键人工智能领域落后,这两个领域都是Siri内部语音辅助功能所必需的,以及新的、更尖端的技术,比如依赖于物体识别的增强现实应用程序。然而,作为苹果的智能语音助手虽然推出也有些年份了,但随着谷歌亚马逊的语音助手的发展,这让苹果预感到了危机,迫切的希望拯救Siri,而Giannandrea似乎就成了合适的人选。
对于教Siri像人类一样理解语言这正是Giannandrea非常擅长的。要知道,Giannandrea从TellMe公司到Metaweb Technologies公司,再到谷歌做的所有工作基本上都属于“自然语言理解(即NLU)”的范畴。
写在最后
当代人工智能可以做三件事:一、对我们询问数据的问题提供更好的答案,二、允许我们提出新类型的问题,三、允许我们完全查询新类型的数据(例如音频、图像和视频以及文字和数字)。而这三件事似乎Siri并没有做好,在很多方面,Siri只是个答录机。因为苹果的隐私政策导致Siri有很多局限性,所以一直被苹果用户吐槽。如果Giannandrea能将Siri在处理数据方面的能力变得更好,或许真的就是Siri起死回生之时。对于苹果的Siri你怎么看?












